|
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Shenyuan Gao,
William Liang,
Kaiyuan Zheng,
Ayaan Malik,
Seonghyeon Ye,
Sihyun Yu,
Wei-Cheng Tseng,
Yuzhu Dong,
Kaichun Mo,
Chen-Hsuan Lin,
Qianli Ma,
Seungjun Nah,
Loic Magne,
Jiannan Xiang,
Yuqi Xie,
Ruijie Zheng,
Dantong Niu,
You Liang Tan,
KR Zentner,
George Kurian,
Suneel Indupuru,
Pooya Jannaty,
Jinwei Gu,
Jun Zhang,
Jitendra Malik,
Pieter Abbeel,
Ming-Yu Liu,
Yuke Zhu*,
Joel Jang* and
Linxi "Jim" Fan*
ICML 2026 (Spotlight)
We introduce 44k hours of diverse human egocentric videos, the largest dataset to date for world model pretraining.
We propose the first robot world model of its kind that demonstrates strong generalization to diverse objects and environments after post-training.
After distillation, our model can achieve long-horizon autoregressive generation, with stable real-time interactions at 10 FPS for over 1 minute.
[Paper]
[Project]
[Code]
[BibTex]
|
|

|
PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation
Wenlong Huang,
Yu-Wei Chao,
Arsalan Mousavian,
Ming-Yu Liu,
Dieter Fox,
Kaichun Mo* and
Li Fei-Fei*
CVPR 2026 (Highlight)
PointWorld is a large pre-trained 3D world model that predicts full-scene 3D point flow from partially observable RGB-D captures and robot actions (represented as 3D point flow).
To train PointWorld, we curate a large-scale dataset spanning real and simulated robotic manipulation in open-world environments, enabled by recent advances in 3D vision and simulated environments, totaling about 2M trajectories and 500 hours across a single-arm Franka and a bimanual humanoid.
We demonstrate that a single pre-trained checkpoint enables a real-world Franka robot to perform rigid-body pushing, deformable and articulated object manipulation, and tool use, without requiring any demonstrations or post-training and all from a single image captured in-the-wild.
[Paper]
[Project]
[Code]
[BibTex]
|
|
|
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Shengyi Qian,
Kaichun Mo,
Valts Blukis,
David Fouhey,
Dieter Fox and
Ankit Goyal
CVPR 2025
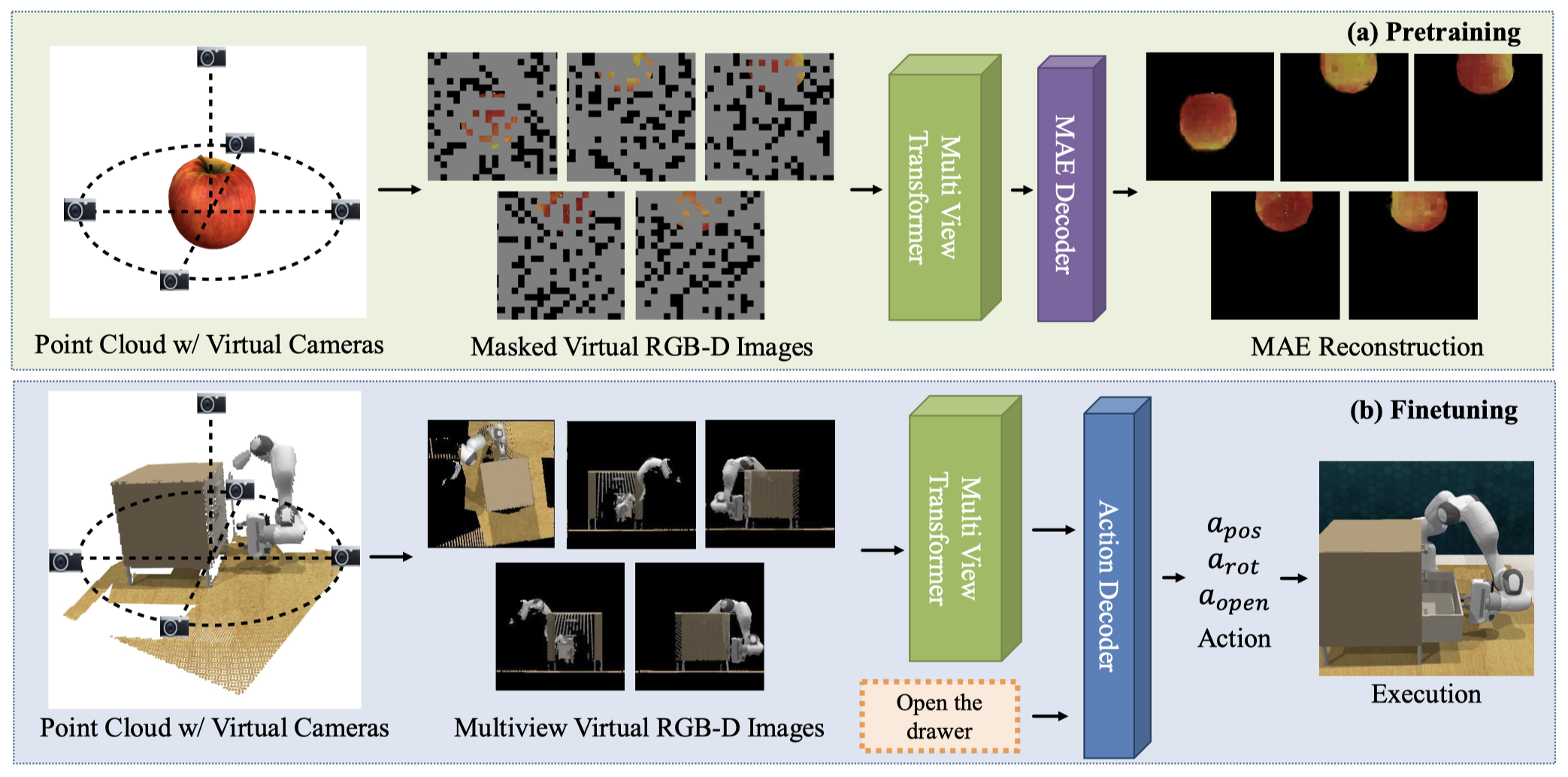
We propose a novel approach for 3D multi-view pretraining using masked autoencoders.
We leverage a multi-view transformer to understand the 3D scene and predict gripper pose actions and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse.
Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies.
[Paper]
[Project]
[BibTex]
|
|

|
Slot-Level Robotic Placement via Visual Imitation from Single Human Video
Dandan Shan,
Kaichun Mo†,
Wei Yang,
Yu-Wei Chao,
David Fouhey,
Dieter Fox and
Arsalan Mousavian
FMEA Workshop, CVPR 2025
We introduce and tackle a novel problem of recognizing and imitating slot-level object robotic placement from a single human demonstration.
This task requires understanding the human video to identify which object is being manipulated (the pick object) and where it is being placed (the placement slot). In addition, it needs to re-identify the pick object and the placement slots during inference along with the relative poses to enable robot execution of the task.
We propose, SLeRP, a modular system that leverages several advanced visual foundation models and a novel slot-level placement detector, SlotNet, eliminating the need for expensive video demonstrations for training.
We evaluate our system using a new benchmark of real-world videos and our system can be deployed on a real robot.
[Paper]
[Project]
[BibTex]
|
|

|
MatchMaker: Automated Robotic Assembly Asset Generation for Policy Learning in Simulation
Yian Wang,
Bingjie Tang,
Chuang Gan,
Dieter Fox,
Kaichun Mo,
Yashraj Narang amd
Iretiayo Akinola
ICRA 2025
We propose MatchMaker, a pipeline to automatically generate diverse, simulation-compatible assembly asset pairs to facilitate learning assembly skills.
Specifically, MatchMaker can 1) take a simulation-incompatible, interpenetrating asset pair as input, and automatically convert it into a simulation-compatible, interpenetration-free pair, 2) take an arbitrary single asset as input , and generate a geometrically-mating asset to create an asset pair, 3) automatically erode contact surfaces from (1) or (2) according to a user-specified clearance parameter to generate realistic parts.
[Paper]
[Project]
[BibTex]
|
|
|
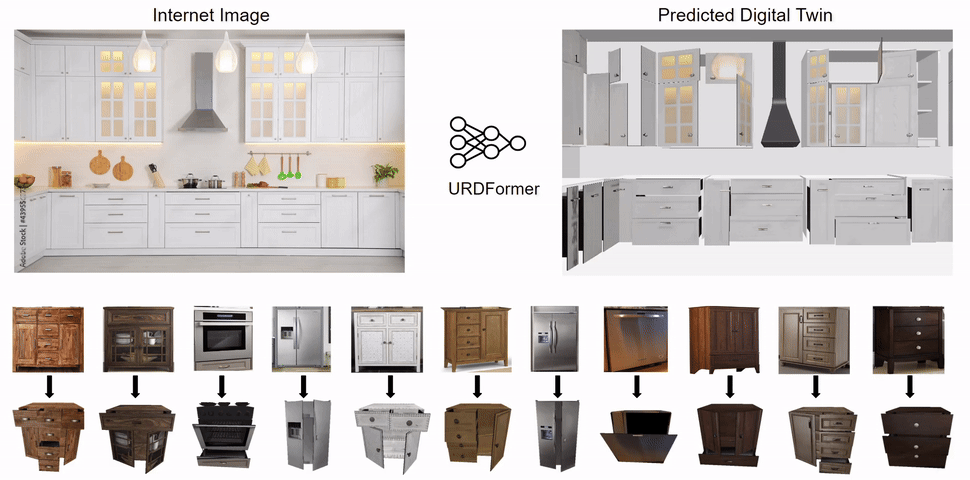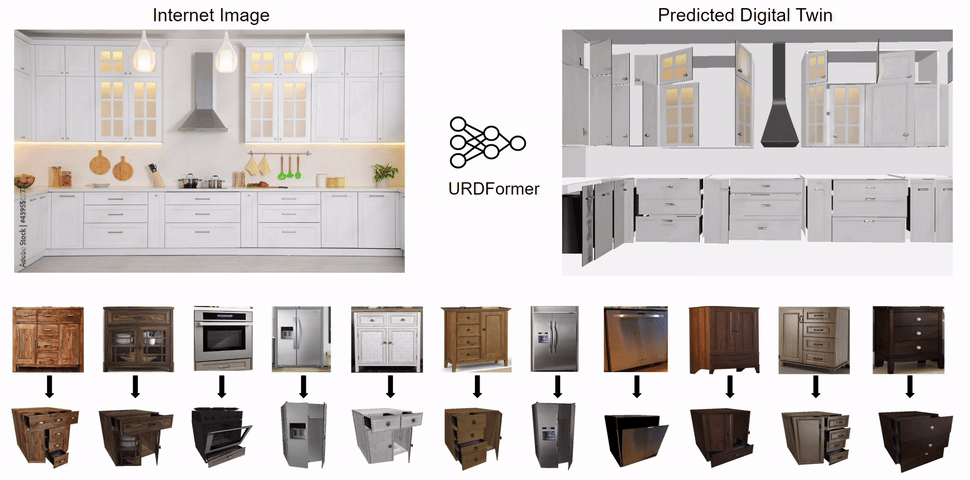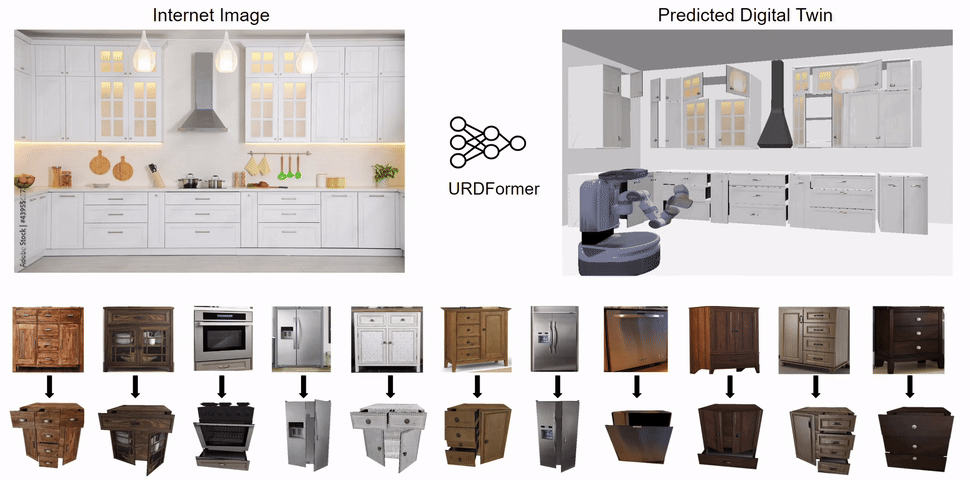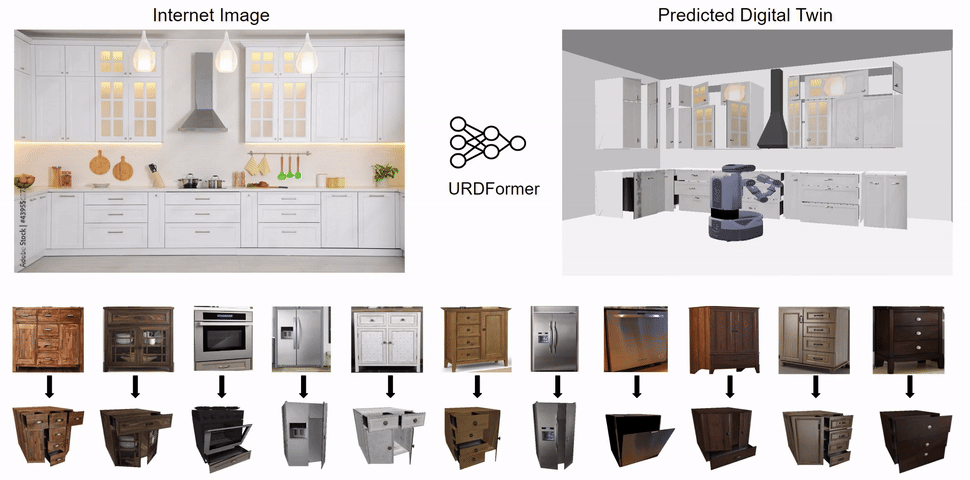
URDFormer: Constructing Interactive Realistic Scenes from Real Images via Simulation and Generative Modeling
Zoey Chen,
Aaron Walsman,
Marius Memmel ,
Kaichun Mo,
Alex Fang,
Karthikeya Vemuri,
Alan Wu,
Dieter Fox* and
Abhishek Gupta*
RSS 2024
We propose URDFormer, a scalable pipeline towards large-scale simulation generation from real-world images.
Given an image (from the internet or captured from a phone), URDFormer predicts its corresponding interactive "digital twin" in the format of a URDF.
This URDF can be loaded into a simulator to train a robot for different tasks.
We present an integrated end-to-end pipeline that generates simulation scenes complete with articulated kinematic and dynamic structures from real-world images and use these for training robotic control policies. We then robustly deploy in the real world for tasks like articulated object manipulation.
[Paper]
[Project]
[Code]
[BibTex]
|
|
|
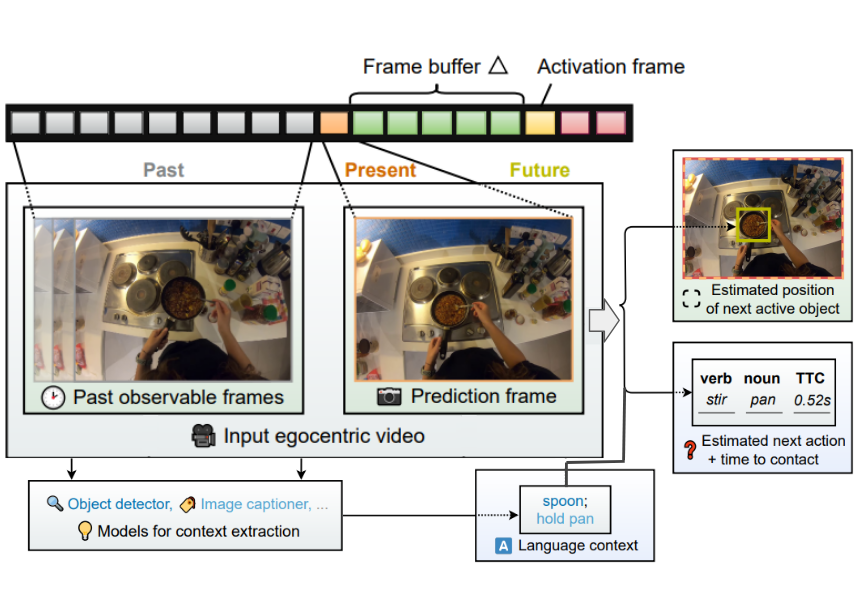
Summarize the Past to Predict the Future: Natural Language Descriptions of Context Boost Multimodal Object Interaction Anticipation
Razvan Pasca,
Alexey Gavryushin,
Muhammad Hamza,
Yen-Ling Kuo,
Kaichun Mo,
Luc Van Gool,
Otmar Hilliges and
Xi Wang
CVPR 2024
We study object interaction anticipation in egocentric videos. This task requires an understanding of the spatiotemporal context formed by past actions on objects, coined action context.
We propose TransFusion, a multimodal transformer-based architecture. It exploits the representational power of language by summarising the action context.
TransFusion leverages pre-trained image captioning and vision-language models to extract the action context from past video frames. This action context together with the next video frame is processed by the multimodal fusion module to forecast the next object interaction.
We have validated the proposed system on the Ego4D data sets.
[Paper]
[Project]
[BibTex]
|
|
|
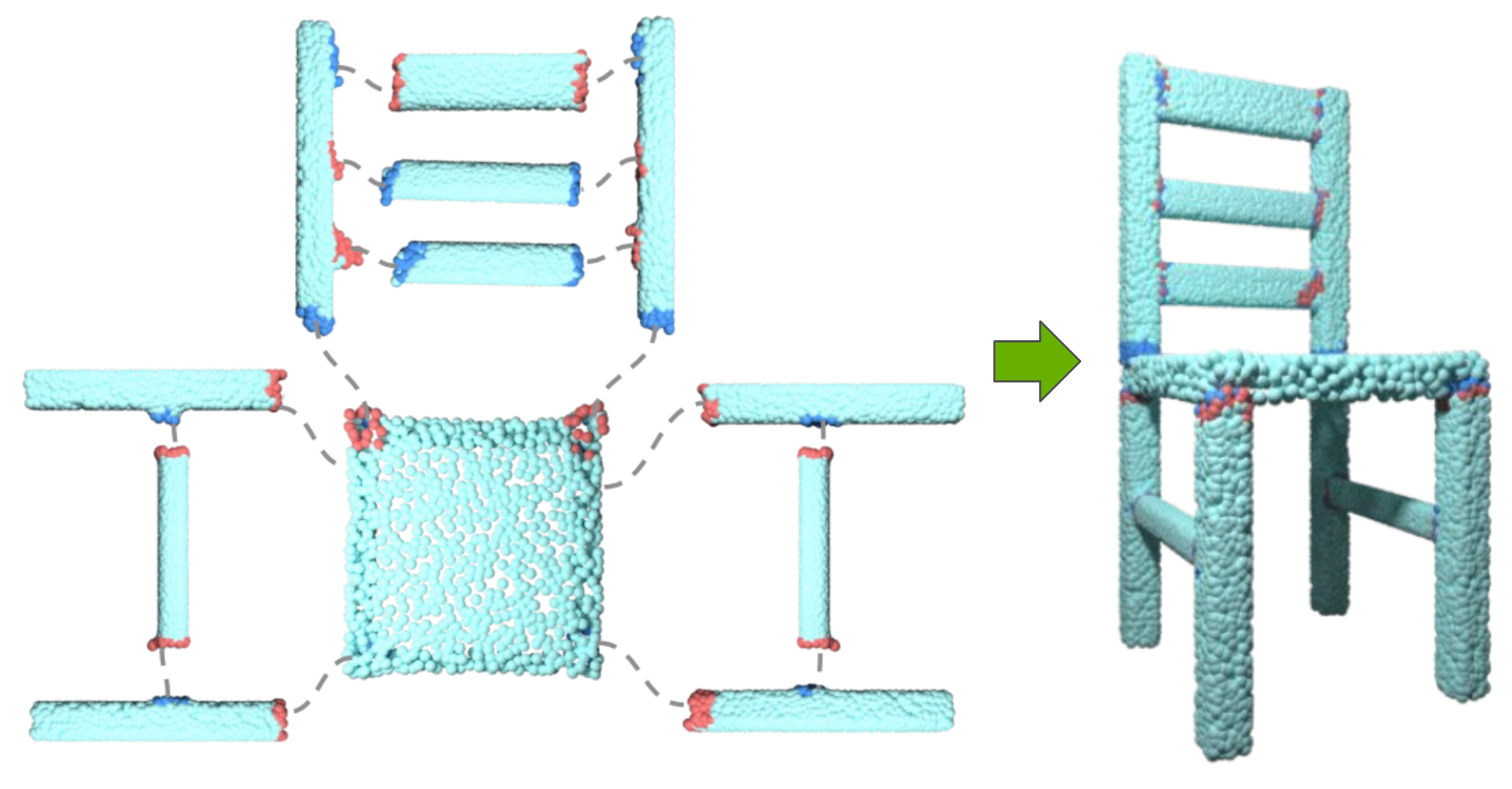
Category-Level Multi-Part Multi-Joint 3D Shape Assembly
Yichen Li,
Kaichun Mo,
Yueqi Duan,
He Wang,
Jiequan Zhang,
Lin Shao,
Wojciech Matusik and
Leonidas J. Guibas
CVPR 2024
We consider the task of joint-aware multi-part 3D shape assembly.
We propose a hierarchical graph learning approach composed of two levels of graph representation learning.
The part graph takes part geometries as input to build the desired shape structure, while the joint-level graph uses part joints information and focuses on matching and aligning joints.
Extensive experiments demonstrate that our method outperforms previous methods, achieving better shape structure and higher joint alignment accuracy.
[Paper]
[BibTex]
|
|
|
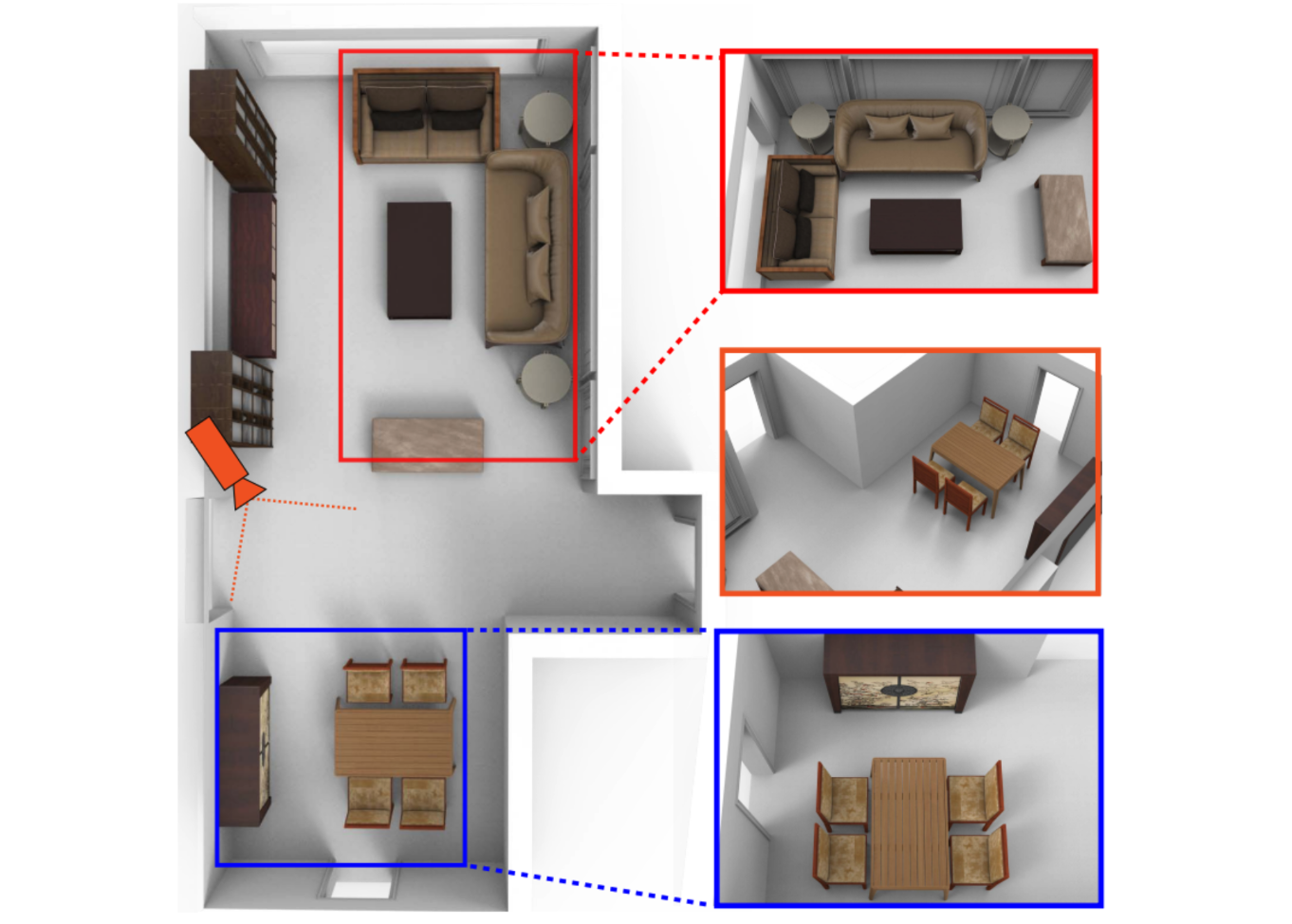
HAISOR: Human-Aware Indoor Scene Optimization via Deep Reinforcement Learning
Jia-Mu Sun,
Jie Yang,
Kaichun Mo,
Yu-Kun Lai,
Leonidas J. Guibas and
Lin Gao
ACM Transactions on Graphics (ToG) 2023, to be presented at
SIGGRAPH 2024
Generative models are powerful in generating 3D scene layouts.
While the generated 3D scenes are seemingly plausible and realistic, they can be functionally unsuitable for humans/robots to navigate and interact with furniture.
To tackle this, we present a human-aware optimization framework for 3D indoor scene arrangement via reinforcement learning.
The HAISOR agent takes advantage of the scene graph representation, Dueling Double DQN, Monte Carlo Tree Search, and Motion Planning techniques for determining a sequence of actions that rearrange the scene towards higher realism and more functional validity.
[Paper]
[Project]
[Video]
[BibTex]
|
|
|
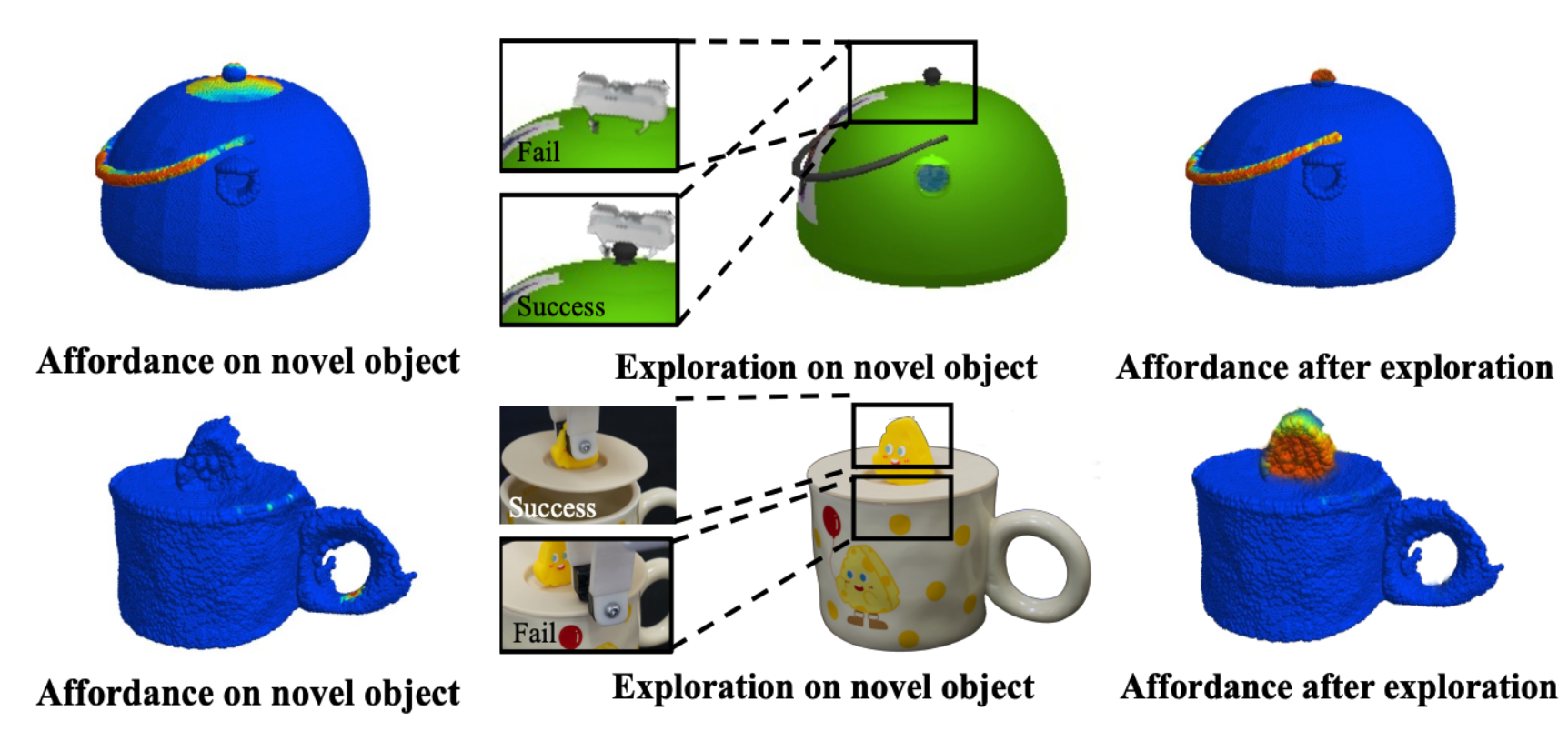
Where2Explore: Few-shot Affordance Learning for Unseen Novel Categories of Articulated Objects
Chuanruo Ning,
Ruihai Wu,
Haoran Lu,
Kaichun Mo and
Hao Dong
NeurIPS 2023
We introduce an affordance learning framework that effectively explores novel categories with minimal interactions on a limited number of instances.
Our framework explicitly estimates the geometric similarity across different categories, identifying local areas that differ from shapes in the training categories for efficient exploration while concurrently transferring affordance knowledge to similar parts of the objects.
Extensive experiments in simulated and real-world environments demonstrate our framework's capacity for efficient few-shot exploration and generalization.
[Paper]
[BibTex]
|
|

|
STOW: Discrete-Frame Segmentation and Tracking of Unseen Objects for Warehouse Picking Robots
Yi Li,
Muru Zhang,
Markus Grotz,
Kaichun Mo and
Dieter Fox
CoRL 2023
Segmentation and tracking of unseen object instances in discrete frames pose a significant challenge in dynamic industrial robotic contexts, such as distribution warehouses.
Our task involves working with a discrete set of frames separated by indefinite periods, during which substantial changes to the scene may occur, such like in the cases of object rearrangements, including shifting, removal, and partial occlusion by new items.
To address these demanding challenges, we introduce new synthetic and real-world datasets that replicate these industrial and household scenarios.
Furthermore, we propose a novel paradigm for joint segmentation and tracking in discrete frames, alongside a transformer module that facilitates efficient inter-frame communication.
Our approach significantly outperforms recent methods in our experiments.
[Paper]
[Project]
[BibTex]
|
|
|
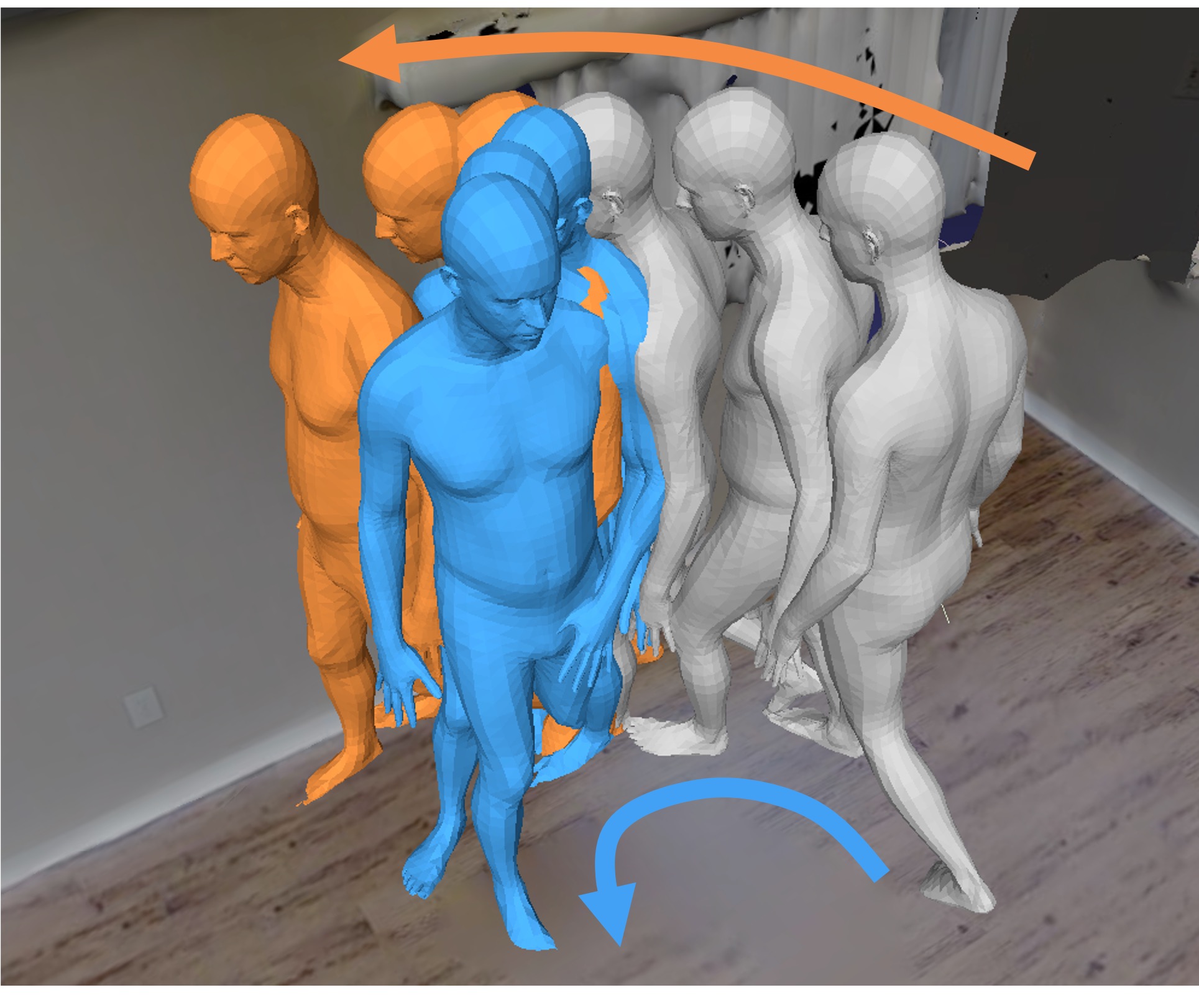
COPILOT: Human Collision Prediction and Localization from Multi-view Egocentric Videos
Boxiao Pan,
Bokui Shen*,
Davis Rempe*,
Despoina Paschalidou,
Kaichun Mo,
Yanchao Yang and
Leonidas J. Guibas
ICCV 2023
We propose the problem of predicting human-scene collisions from multi-view egocentric RGB videos captured from an exoskeleton.
Specifically, the problem consists of predicting: (1) if a collision will happen in the next H seconds; (2) which body joints might be involved in a collision; and (3) where in the scene might cause the collision, in the form of a spatial heatmap.
To solve this problem, we present COPILOT, a COllision PredIction and LOcalization Transformer that tackles all three sub-tasks in a multi-task setting, effectively leveraging multi-view video inputs through a proposed 4D attention operation across space, time, and viewpoint.
[Paper]
[Project]
[BibTex]
|
|
|
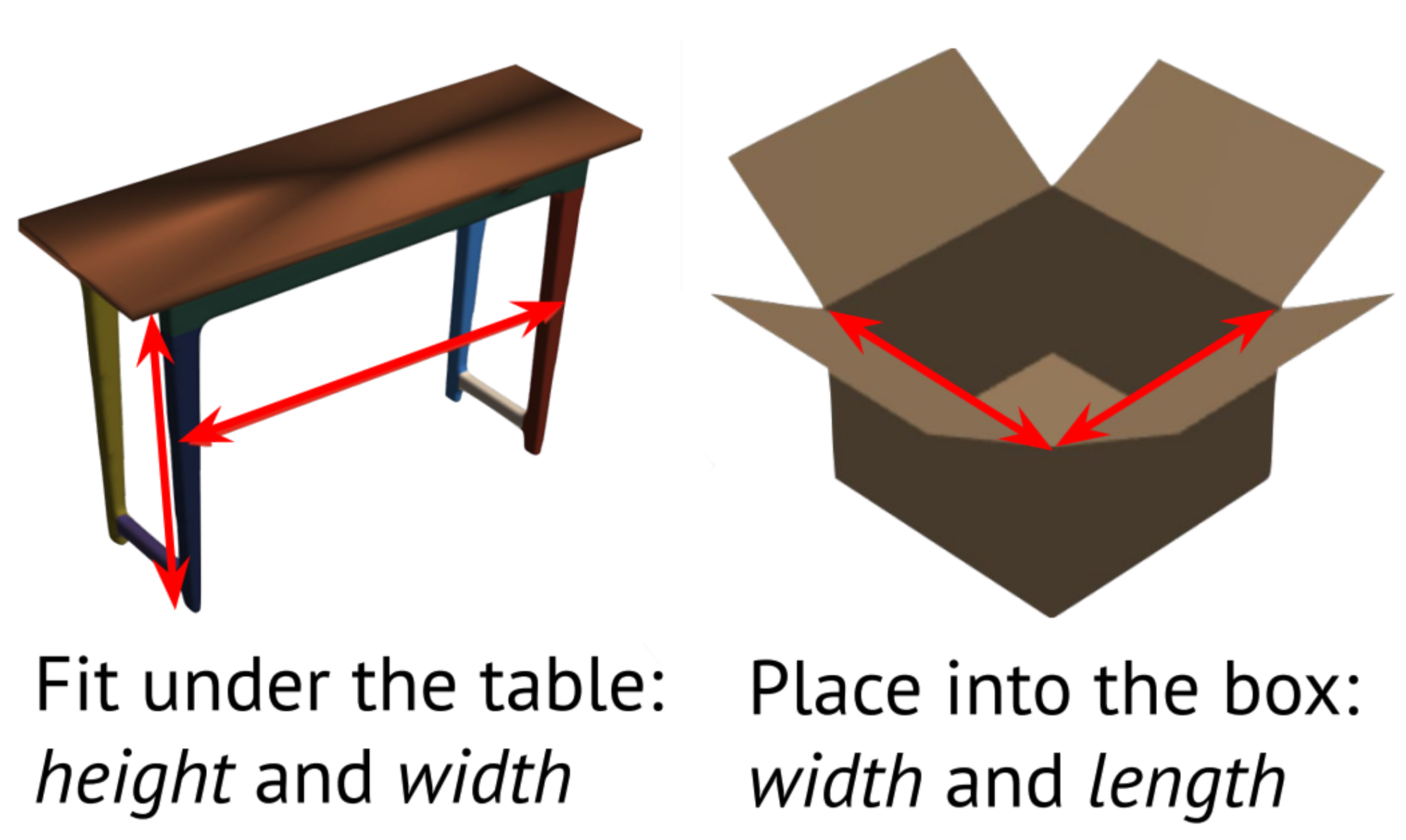
Toward Learning Geometric Eigen-Lengths Crucial for Fitting Tasks
Yijia Weng,
Kaichun Mo,
Ruoxi Shi,
Yanchao Yang and
Leonidas J. Guibas
ICML 2023
Some extremely low-dimensional yet crucial geometric eigen-lengths often determine the success of some geometric tasks.
For example, the height of an object is important to measure to check if it can fit between the shelves of a cabinet, while the width of a couch is crucial when trying to move it through a doorway.
In this work, we propose a novel problem of discovering key geometric concepts (e.g., height, width, radius) of objects for robotic fitting tasks.
We explore potential solutions and demonstrate the feasibility of learning eigen-lengths from simply observing successful and failed fitting trials.
We also attempt geometric grounding for more accurate eigen-length measurement and study the reusability of the learned geometric eigen-lengths across multiple tasks.
[Project]
[BibTex]
|
|

|
JacobiNeRF: NeRF Shaping with Mutual Information Gradients
Xiaomeng Xu*,
Yanchao Yang*,
Kaichun Mo,
Boxiao Pan,
Li Yi and
Leonidas J. Guibas
CVPR 2023
We propose a method that trains a neural radiance field (NeRF) to encode not only the appearance of the scene but also mutual correlations between scene points, regions, or entities – aiming to capture their co-variation patterns.
In contrast to the traditional first-order photometric reconstruction objective, our method explicitly regularizes the learning dynamics to align the Jacobians of highlycorrelated entities, which proves to maximize the mutual information between them under random scene perturbations.
Experiments show that JacobiNeRF is more efficient in propagating annotations among 2D pixels and 3D points compared to NeRFs without mutual information shaping, especially in extremely sparse label regimes – thus reducing annotation burden.
[Paper]
[Code]
[Poster]
[Slides]
[BibTex]
|
|

|
DualAfford: Learning Collaborative Visual Affordance for Dual-gripper Object Manipulation
Yan Zhao*,
Ruihai Wu*,
Zhehuan Chen,
Yourong Zhang,
Qingnan Fan,
Kaichun Mo and
Hao Dong
ICLR 2023
We propose a novel learning framework, DualAfford, to learn collaborative affordance for dual-gripper manipulation tasks.
The core design of the approach is to reduce the quadratic problem for two grippers into two disentangled yet interconnected subtasks for efficient learning.
Using the large-scale PartNet-Mobility and ShapeNet datasets, we set up four benchmark tasks for dual-gripper manipulation.
[Paper]
[Project]
[BibTex]
|
|
|
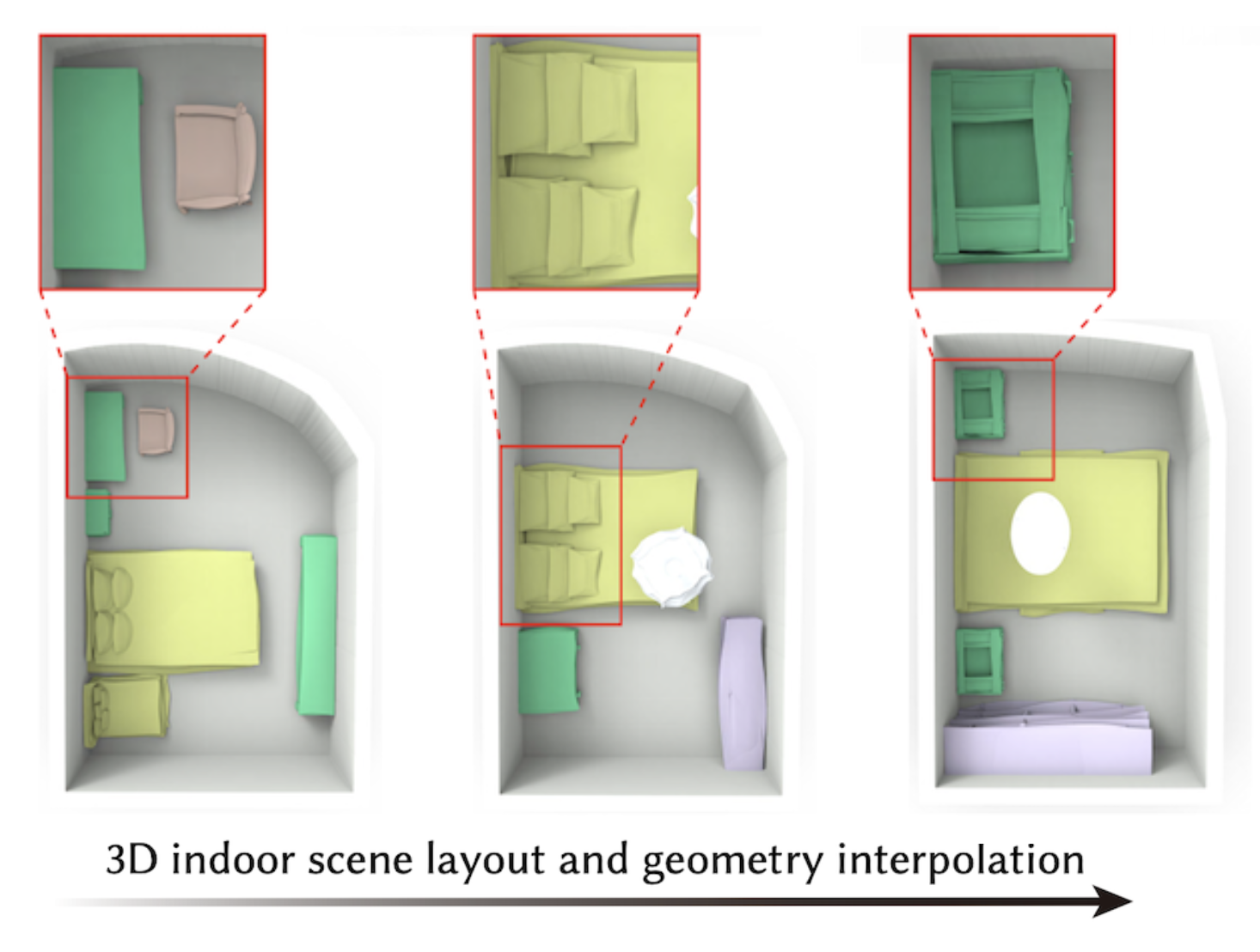
SceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry
Lin Gao,
Jia-Mu Sun,
Kaichun Mo,
Yu-Kun Lai,
Leonidas J. Guibas and
Jie Yang
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2023
We propose a hierarchical graph network for 3D indoor scenes that takes into account the full hierarchy from the room level to the object level, then finally to the object part level.
Therefore for the first time, our method is able to directly generate plausible 3D room content, including furniture objects with fine-grained geometry, and their layout.
Our generation network is a conditional recursive neural network (RvNN) based variational autoencoder (VAE) that learns to generate detailed content with fine-grained geometry for a room, given the room boundary as the condition.
Extensive experiments demonstrate that our method produces superior generation results.
We also demonstrate that our method is effective for various applications such as part-level room editing, room interpolation, and room generation by arbitrary room boundaries.
[Paper]
[Project]
[BibTex]
|
|
|
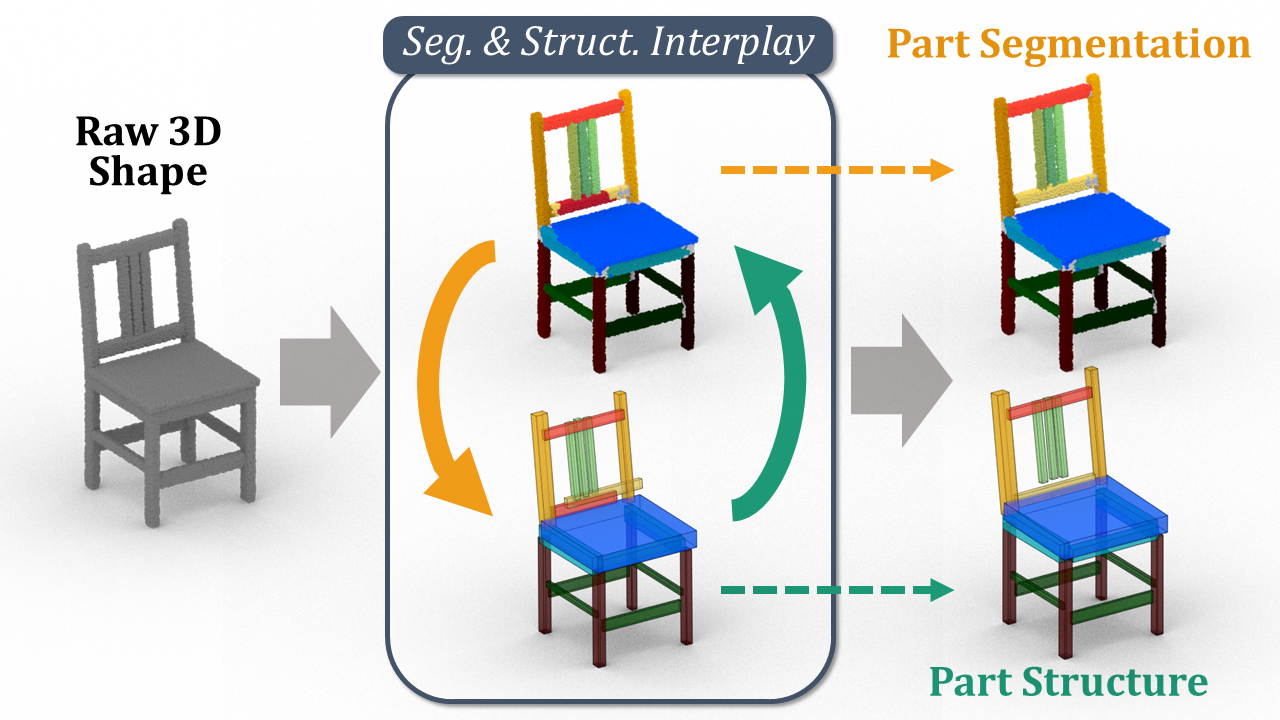
Seg&Struct: The Interplay between Part Segmentation and Structure Inference for 3D Shape Parsing
Jeonghyun Kim,
Kaichun Mo,
Minhyuk Sung* and
Woontack Woo*
WACV 2023
We propose Seg& Struct, a supervised learning framework leveraging the interplay between part segmentation and structure inference and demonstrating their synergy in an integrated framework.
Our framework first decomposes a raw input shape into part segments using off-the-shelf algorithm, whose outputs are then mapped to nodes in a part hierarchy, establishing point-to-part associations.
Following this, ours predicts the structural information, e.g., part bounding boxes the part relationships.
Lastly, the segmentation is rectified by examining the confusion of part boundaries using the structure-based part features.
[Paper]
[Project]
[BibTex]
|
|
|
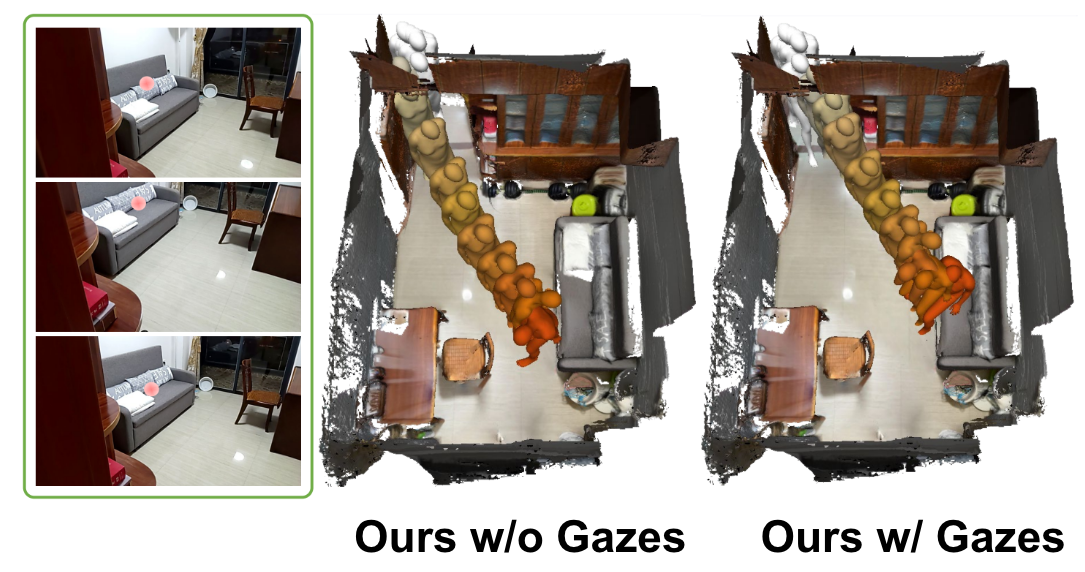
GIMO: Gaze-Informed Human Motion Prediction in Context
Yang Zheng,
Yanchao Yang,
Kaichun Mo,
Jiaman Li,
Tao Yu,
Yebin Liu,
Karen Liu and
Leonidas J. Guibas
ECCV 2022
We propose a large-scale human motion dataset that delivers high-quality body pose sequences, scene scans, as well as ego-centric views with eye gaze that serves as a surrogate for inferring human intent.
After adapting and benchmarking existing state-of-the-art methods, we introduce a novel network architecture that enables bidirectional communication between the gaze and motion branches for better ego-centric human motion predictions.
[Paper]
[Project]
[BibTex]
|
|
|
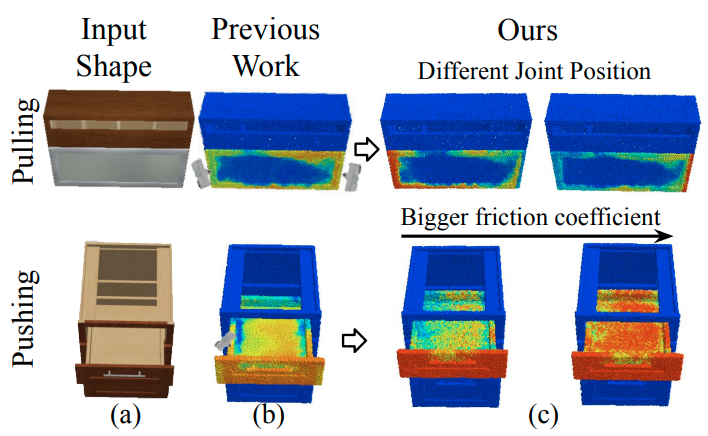
AdaAfford: Learning to Adapt Manipulation Affordance for 3D Articulated Objects via Few-shot Interactions
Yian Wang*,
Ruihai Wu*,
Kaichun Mo*,
Jiaqi Ke,
Qingnan Fan,
Leonidas J. Guibas and
Hao Dong
ECCV 2022
Taking only passive observations as inputs, Where2Act ignores many hidden but important kinematic constraints (e.g., joint location and limits) and dynamic factors (e.g., joint friction and restitution), therefore losing significant accuracy for test cases with such uncertainties. In this paper, we propose a novel framework, named AdaAfford, that learns to perform very few test-time interactions for quickly adapting the affordance priors to more accurate instance-specific posteriors.
[Paper]
[Project]
[BibTex]
|
|
|
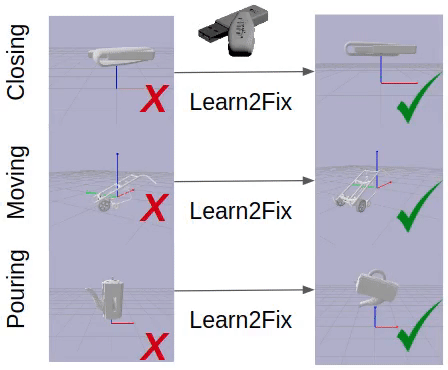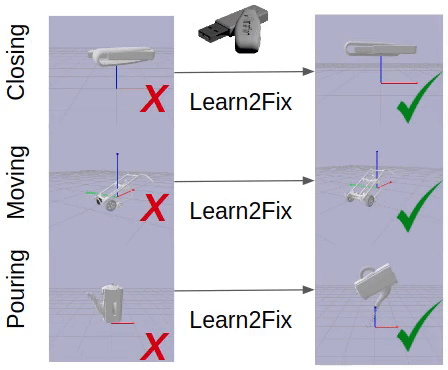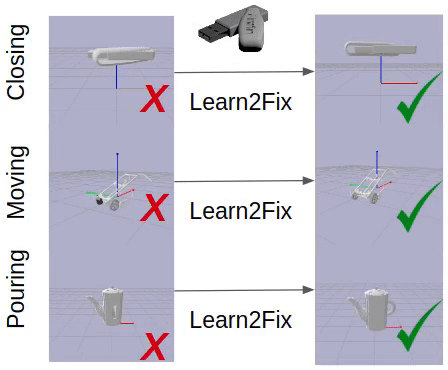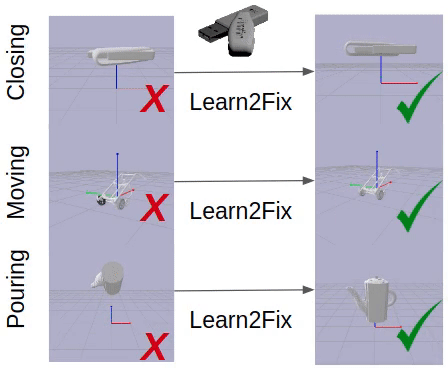
Fixing Malfunctional Objects With Learned Physical Simulation and Functional Prediction
Yining Hong,
Kaichun Mo,
Li Yi,
Leonidas J. Guibas,
Antonio Torralba,
Joshua Tenenbaum and
Chuang Gan
CVPR 2022
This paper studies the problem of fixing malfunctional 3D objects.
Given a malfunctional object, humans can perform mental simulations to reason about its functionality and figure out how to fix it.
We propose FixIt, a dataset that contains around 5k poorly-designed 3D physical objects paired with choices to fix them.
We present FixNet, a novel framework that seamlessly incorporates perception and physical dynamics.
Specifically, FixNet consists of a perception module to extract the structured representation from the 3D point cloud, a physical dynamics prediction module to simulate the results of interactions on 3D objects, and a functionality prediction module to evaluate the functionality and choose the correct fix.
[Paper]
[Project]
[Video]
[BibTex]
|
|
|
IFR-Explore: Learning Inter-object Functional Relationships in 3D Indoor Scenes
Qi Li*,
Kaichun Mo*,
Yanchao Yang,
Hang Zhao and
Leonidas J. Guibas
ICLR 2022
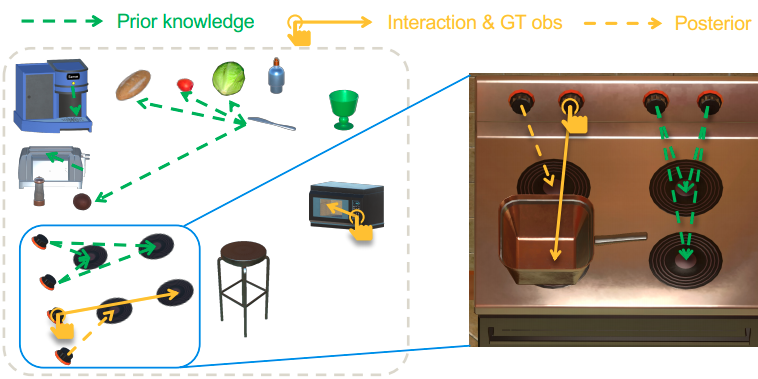
We take the first step in building AI system learning inter-object functional relationships in 3D indoor environments (e.g., a switch on the wall turns on or off the light, a remote control operates the TV).
The key technical contributions are modeling prior knowledge by training over large-scale scenes and designing interactive policies for effectively exploring the training scenes and quickly adapting to novel test scenes.
[Paper]
[Code]
[BibTex]
|
|

|
Object Pursuit: Building a Space of Objects via Discriminative Weight Generation
Chuanyu Pan*,
Yanchao Yang*,
Kaichun Mo,
Yueqi Duan and
Leonidas J. Guibas
ICLR 2022
We propose a framework to continuously learn object-centric representations for visual learning and
understanding.
Our method leverages interactions to effectively sample diverse variations of an object and the corresponding training signals while learning the object-centric representations.
Throughout learning, objects are streamed one by one in random order with unknown identities, and
are associated with latent codes that can synthesize discriminative weights for each object through
a convolutional hypernetwork.
[Paper]
[Code]
[BibTex]
|
|

|
VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects
Ruihai Wu*,
Yan Zhao*,
Kaichun Mo*,
Zizheng Guo,
Yian Wang,
Tianhao Wu,
Qingnan Fan,
Xuelin Chen,
Leonidas J. Guibas and
Hao Dong
ICLR 2022
Awards:
Youth Outstanding Paper Award at WAIC 2025
We propose object-centric actionable visual priors as a novel perception-interaction handshaking point that the perception system outputs more actionable guidance than kinematic structure estimation, by predicting dense geometry-aware, interaction-aware, and task-aware visual action affordance and trajectory proposals.
We design an interaction-for-perception framework VAT-Mart to learn such actionable visual representations by simultaneously training a curiosity-driven reinforcement learning policy exploring diverse interaction trajectories and a perception module summarizing and generalizing the explored knowledge for pointwise predictions among diverse shapes.
[Paper]
[Project]
[Video]
[BibTex]
|
|
|
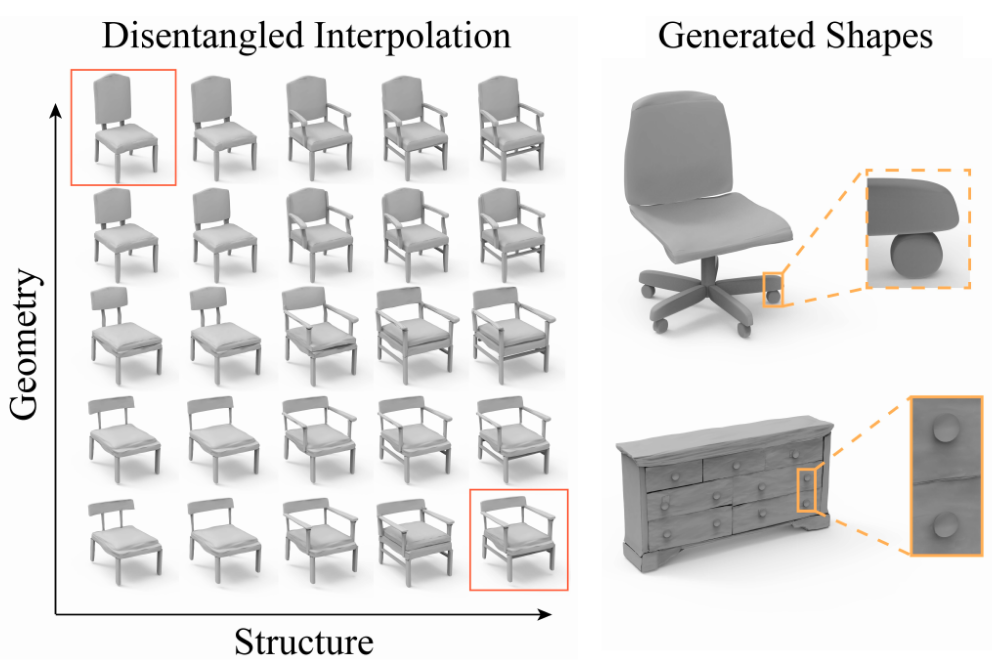
DSG-Net: Learning Disentangled Structure and Geometry for 3D Shape Generation
Jie Yang*,
Kaichun Mo*,
Yu-Kun Lai,
Leonidas J. Guibas and
Lin Gao
ACM Transactions on Graphics (ToG) 2022, to be presented at
SIGGRAPH 2022
We introduce DSG-Net, a deep neural network that learns a disentangled structured mesh representation for 3D shapes, where two key aspects of shapes, geometry and structure, are encoded in a synergistic manner to ensure plausibility of the generated shapes, while also being disentangled as much as possible. This supports a range of novel shape generation applications with intuitive control, such as interpolation of structure (geometry) while keeping geometry (structure) unchanged.
Our method not only supports controllable generation applications, but also produces high-quality synthesized shapes.
[Paper]
[Project]
[Video]
[BibTex]
|
|
|
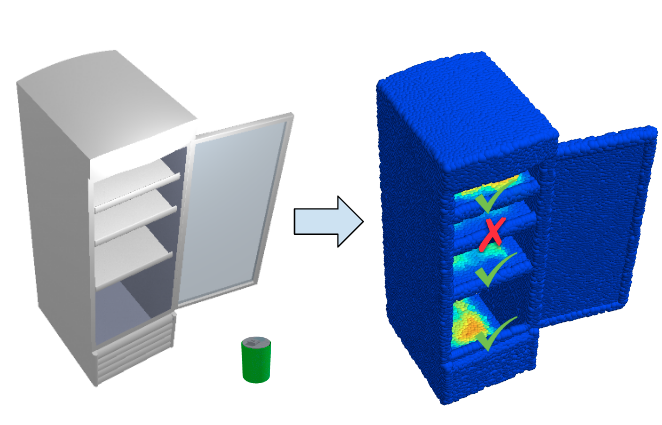
O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning
Kaichun Mo,
Yuzhe Qin,
Fanbo Xiang,
Hao Su and
Leonidas J. Guibas
CoRL 2021
Contrary to the vast literature in modeling, perceiving, and understanding agent-object interaction in computer vision and robotics, very few past works have studied the task of object-object interaction, which also plays an important role in robotic manipulation and planning tasks.
There is a rich space of object-object interaction scenarios in our daily life, such as placing an object on a messy tabletop, fitting an object inside a drawer, pushing an object using a tool, etc.
In this paper, we propose a large-scale object-object affordance learning framework that requires no human annotation or demonstration.
[Paper]
[Project]
[Video]
[BibTex]
|
|

|
Learning to Regrasp by Learning to Place
Shuo Cheng,
Kaichun Mo and
Lin Shao
CoRL 2021
Regrasping is needed whenever a robot's current grasp pose fails to perform desired manipulation tasks.
In this paper, we propose a system for robots to take partial point clouds of an object and the supporting environment as inputs and output a sequence of pick-and-place operations to transform an initial object grasp pose to the desired object grasp poses. The key technique includes a neural stable placement predictor and a regrasp graph based solution through leveraging and changing surrounding environment.
[Paper]
[Project]
[BibTex]
|
|
|
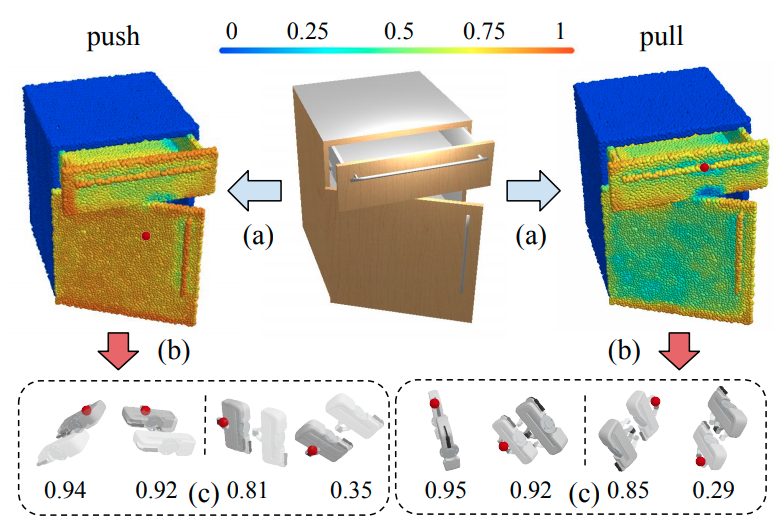
Where2Act: From Pixels to Actions for Articulated 3D Objects
Kaichun Mo,
Leonidas J. Guibas,
Mustafa Mukadam,
Abhinav Gupta and
Shubham Tulsiani
ICCV 2021
Featured in:
VentureBeat,
Google AI Blog
One of the fundamental goals of visual perception is to allow agents to meaningfully interact with their environment.
In this paper, we take a step towards that long-term goal -- we extract highly localized actionable information related to elementary actions such as pushing or pulling for articulated objects with movable parts.
We propose, discuss, and evaluate novel network architectures that given image and depth data, predict the set of actions possible at each pixel, and the regions over articulated parts that are likely to move under the force. We propose a learning-from-interaction framework with an online data sampling strategy that allows us to train the network in simulation (SAPIEN) and generalizes across categories.
[Paper]
[Project]
[Video]
[BibTex]
|
|
|
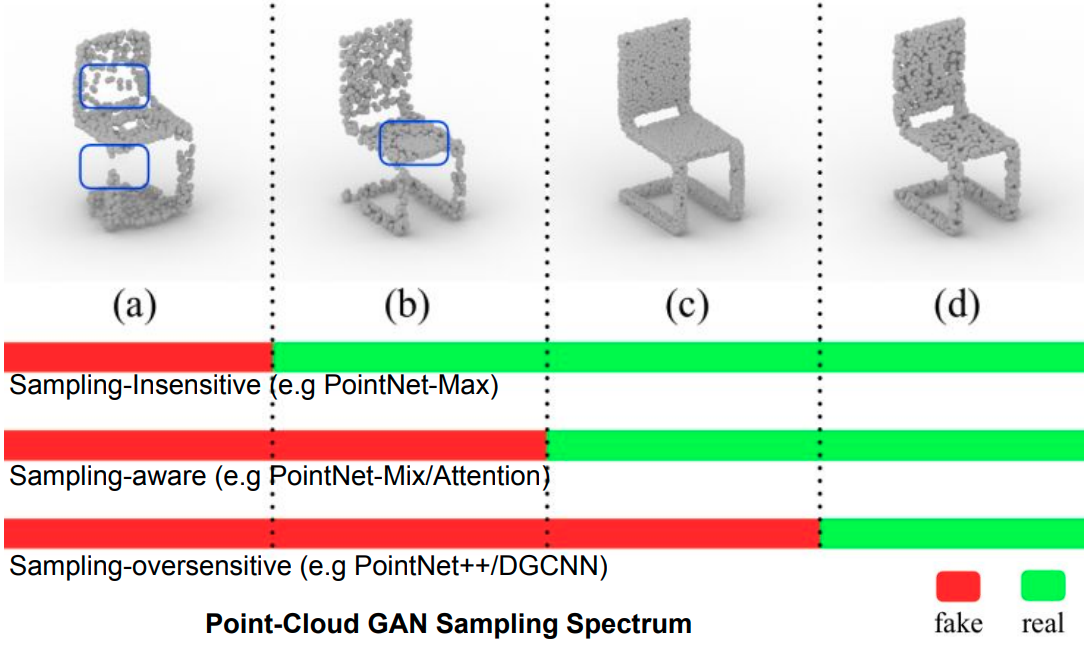
Rethinking Sampling in 3D Point Cloud Generative Adversarial Networks
He Wang*,
Zetian Jiang*,
Li Yi,
Kaichun Mo,
Hao Su and
Leonidas J. Guibas
CVPR 2021 Workshop "Learning to generate 3D Shapes and Scenes"
We show that sampling-insensitive discriminators (e.g.PointNet-Max) produce shape point clouds with point clustering artifacts while sampling-oversensitive discriminators (e.g.PointNet++, DGCNN) fail to guide valid shape generation.
We propose the concept of sampling spectrum to depict the different sampling sensitivities of discriminators.
We point out that, though recent research has been focused on the generator design, the main bottleneck of point cloud GAN actually lies in the discriminator design.
[Paper]
[BibTex]
|
|
|
Generative 3D Part Assembly via Dynamic Graph Learning
Jialei Huang*,
Guanqi Zhan*,
Qingnan Fan,
Kaichun Mo,
Lin Shao,
Baoquan Chen,
Leonidas J. Guibas and
Hao Dong
NeurIPS 2020
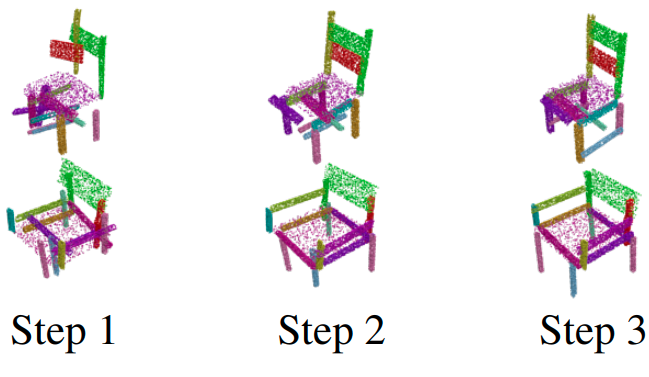
Analogous to buying an IKEA furniture, given a set of 3D part point clouds, we predict 6-Dof part poses to assemble a 3D shape.
To tackle this problem, we propose an assembly-oriented dynamic graph learning framework that leverages an iterative graph neural network as a backbone.
It explicitly conducts sequential part assembly refinements in a coarse-to-fine manner, exploits a pair of part relation reasoning module and part aggregation module for dynamically adjusting both part features and their relations in the part graph.
[Paper]
[Project]
[BibTex]
|
|
|
Learning 3D Part Assembly from a Single Image
Yichen Li*,
Kaichun Mo*,
Lin Shao,
Minhyuk Sung and
Leonidas J. Guibas
ECCV 2020
(Also be present at Holistic Scene Structures for 3D Vision)
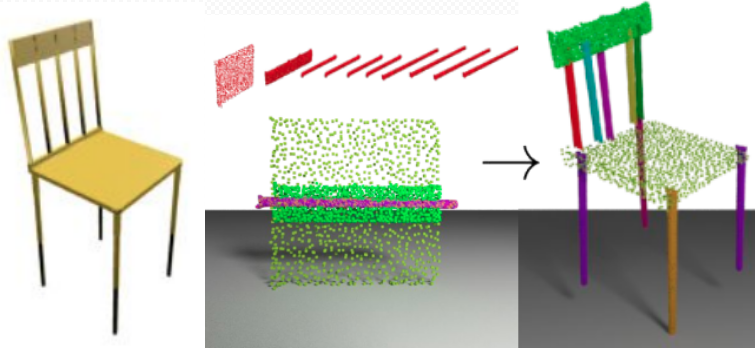
We introduce a novel problem, single-image-guided 3D part assembly, that assembles 3D shapes from parts given a complete set of part point cloud scans and a single 2D image depicting the object.
The task is motivated by the robotic assembly setting and the estimated per-part poses serve as a vision-based initialization before robotic planning and control components.
[Paper]
[Project]
[Video (1-min)]
[Video (7-min)]
[BibTex]
|
|
|
PT2PC: Learning to Generate 3D Point Cloud Shapes from Part Tree Conditions
Kaichun Mo,
He Wang,
Xinchen Yan and
Leonidas J. Guibas
ECCV 2020
This paper investigates the novel problem of generating 3D shape point cloud geometry from a symbolic part tree representation.
In order to learn such a conditional shape generation procedure in an end-to-end fashion, we propose a conditional GAN "part tree"-to-"point cloud" model (PT2PC) that disentangles the structural and geometric factors.
[Paper]
[Project]
[Video (1-min)]
[Video (10-min)]
[BibTex]
|
|

|
SAPIEN: A SimulAted Part-based Interactive ENvironment
Fanbo Xiang,
Yuzhe Qin,
Kaichun Mo,
Yikuan Xia,
Hao Zhu,
Fangchen Liu,
Minghua Liu,
Hanxiao Jiang,
Yifu Yuan,
He Wang,
Li Yi,
Angel X.Chang,
Leonidas J. Guibas and
Hao Su
CVPR 2020, Oral Presentation
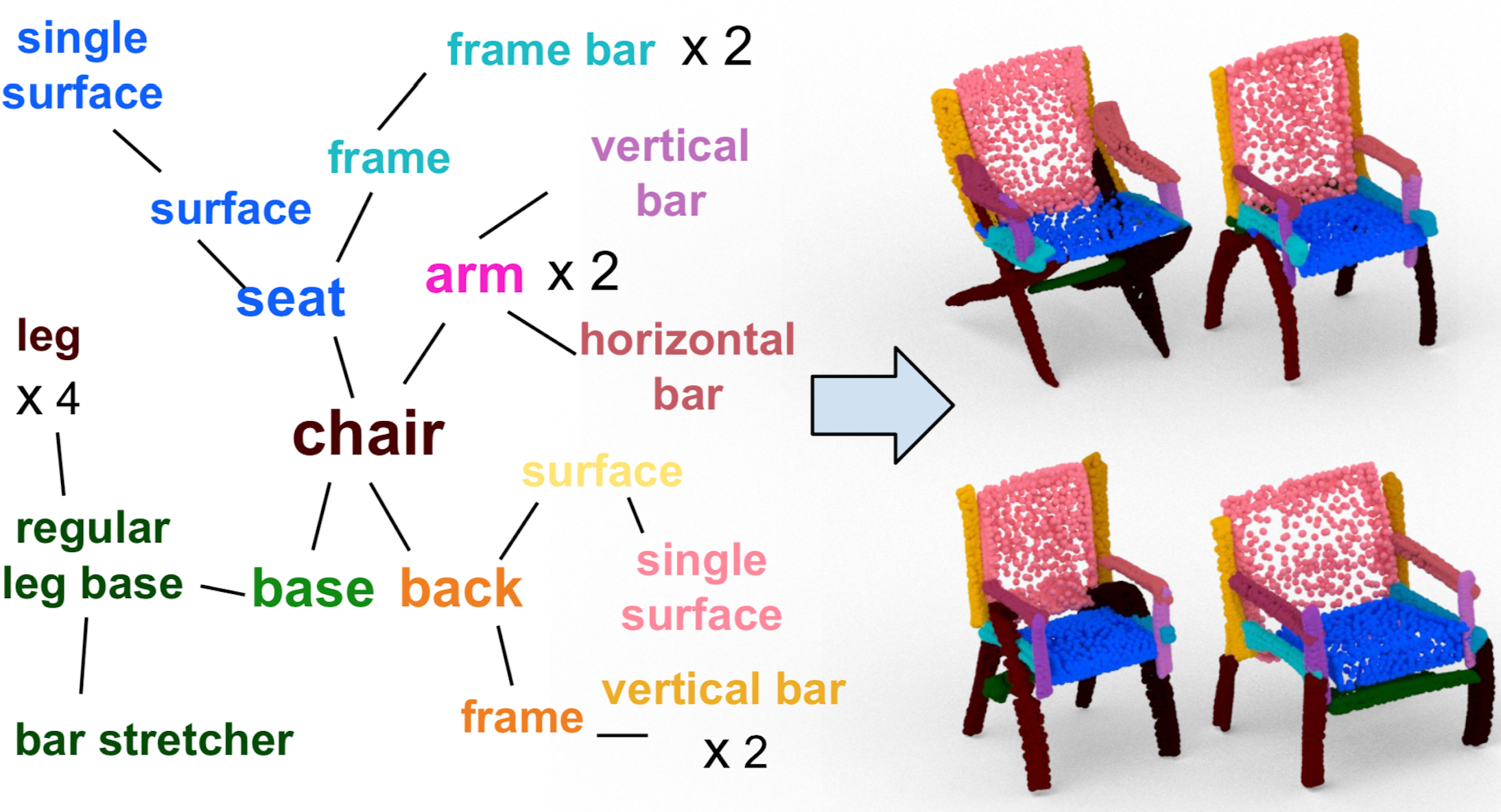
We propose a realistic and physics-rich simulation environment hosting large-scale 3D articulated objects from ShapeNet and PartNet.
Our PartNet-Mobility dataset contains 14,068 articulated parts with part motion information for 2,346 object models from 46 common indoor object categories.
SAPIEN enables various robotic vision and interaction tasks that require detailed part-level understanding.
[Paper]
[Project Page]
[Code]
[Demo]
[Video]
[BibTex]
|
|
|
StructEdit: Learning Structural Shape Variations
Kaichun Mo*,
Paul Guerrero*,
Li Yi,
Hao Su,
Peter Wonka,
Niloy Mitra and
Leonidas J. Guibas
CVPR 2020
Featured in:
CVPR Daily (Tue)
Video:
CVPR Workshop: Learning 3D Generative Models (Invited Talk By Paul Guerrero)
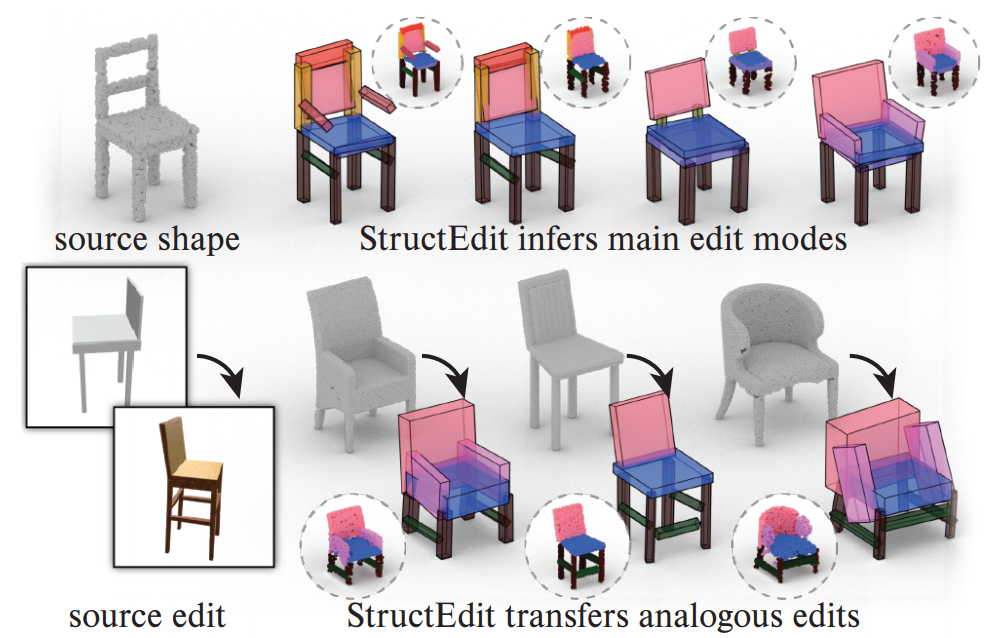
We learn local shape edits (shape deltas) space that captures both discrete structural changes and continuous variations.
Our approach is based on a conditional variational autoencoder (cVAE) for encoding and decoding shape deltas, conditioned on a source shape.
The learned shape delta spaces support shape edit suggestions, shape analogy, and shape edit transfer, much better than StructureNet, on the PartNet dataset.
[Paper]
[Project]
[Video]
[BibTex]
|
|
|
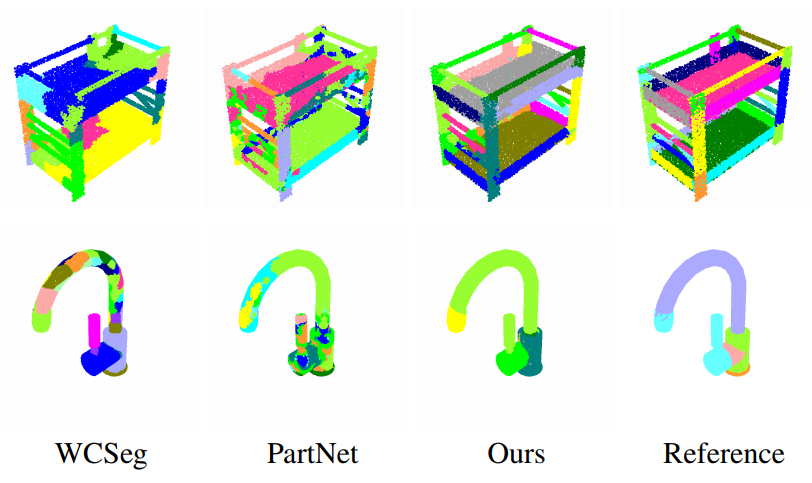
Learning to Group: A Bottom-Up Framework for 3D Part Discovery in Unseen Categories
Tiange Luo,
Kaichun Mo,
Zhiao Huang,
Jiarui Xu,
Siyu Hu,
Liwei Wang and
Hao Su
ICLR 2020
We address the problem of learning to discover 3D parts for objects in unseen categories under the zero-shot learning setting.
We propose a learning-based iterative grouping framework which learns a grouping policy to progressively merge small part proposals into bigger ones in a bottom-up fashion.
On PartNet, we demonstrate that our method can transfer knowledge of parts learned from 3 training categories to 21 unseen categories.
[Paper]
[Project]
[Video]
[BibTex]
|
|